5.2 KiB
Operator/expression 's Backward
Motivation
In Neural Network, most models are solved by the backpropagation algorithm(known as BP) at present. Technically, BP calculates the gradient of the loss function, then propagates it back through the networks following the chain rule. Hence we need a module that chains the gradient operators/expressions together to construct the backward pass. Every forward network needs a backward network to construct the full computation graph. The operator/expression's backward pass will be generated with respect to the forward pass.
Implementation
In this design doc, we exported only one API for generating the backward pass.
std::unique_ptr<OperatorBase> Backward(const OperatorBase& forwardOp,
const std::unordered_set<std::string>& no_grad_vars);
The implementation behind it can be divided into two parts, Backward Operator Creating and Backward Operator Building.
Backward Operator Registry
A backward network is built up with several backward operators. Backward operators take forward operators' inputs, outputs, and output gradients and then calculate its input gradients.
| forward operator | backward operator | |
|---|---|---|
| Operator::inputs_ | Inputs | Inputs, Outputs, OutputGradients |
| Operator::outputs_ | Outputs | InputGradients |
In most cases, there is a one-to-one relation between the forward and backward operators. These relations are recorded by a global hash map(OpInfoMap). To follow the philosophy of minimum core and to make operators pluggable, the registry mechanism is introduced.
For example, we have mul_op, and we can register its information and corresponding backward operator by the following macro:
REGISTER_OP(mul, MulOp, MulOpMaker, mul_grad, MulOpGrad);
mul is the operator's type. MulOp and MulOpMaker are the operator class and the operator maker class respectively.
mul_grad is the type of backward operator, and MulOpGrad is its class name.
Backward Opeartor Creating
Given a certain forward operator, we can get its corresponding backward operator by calling:
OperatorBase* bwd_op = BuildGradOp(const OperatorBase* fwd_op);
The function BuildGradOp will sequentially execute following processes:
-
Get the
type_of given forward operator, and then get the corresponding backward operator's type by looking up theOpInfoMap. -
Build two maps named
inputsandoutputsto temporarily store backward operator's inputs and outputs. Copy forward operator'sinputs_andoutputs_to mapinputs, except these, are not necessary for gradient computing. -
Add forward inputs' gradient variables into map
output, adding forward outputs' gradient variables into mapinput. -
Building backward operator with
inputs,outputsand forward operator's attributes.
Backward Network Building
A backward network is a series of backward operators. The main idea of building a backward network is creating backward operators in the inverted sequence and appending them together one by one. There are some corner cases that need special processing.
-
Op
When the input forward network is an Op, return its gradient Operator immediately. If all of its outputs are in no gradient set, then return a special
NOP. -
NetOp
In our design, the network itself is also a kind of operator(NetOp). So the operators contained by a big network may be some small network. When the input forward network is a NetOp, it needs to call the sub NetOp/Operators backward function recursively. During the process, we need to collect the
OutputGradientsname according to the forward NetOp. -
RnnOp
RnnOp is a nested stepnet operator. Backward module needs to recusively call
Backwardfor every stepnet. -
Sharing Variables
As illustrated in the figure 1 and figure 2, two operators share the same variable name W@GRAD, which will overwrite their shared input variable.

Figure 1. Sharing variables in operators.
Sharing variable between operators or same input variable used in multiple operators can lead to duplicate gradient variables. As illustrated in figure 2, we need to rename the gradient names recursively and add a generic add operator to prevent overwriting.
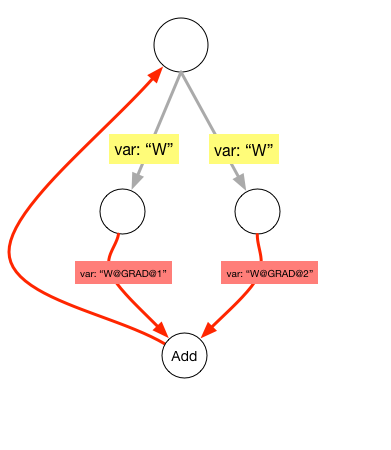
Figure 2. Replace sharing variable's gradient with Add operator.
Because the framework finds variables according to their names, we need to rename the output links. We add an integer suffix to represent its position in the clockwise direction.
-
Part of the Gradient is Zero.
In the whole graph, there is some case of that one operator's gradient is not needed, but its input's gradient is a dependency link of other operator, we need to fill a same shape gradient matrix in the position. In our implementation, we insert a special
fillZeroLikeoperator.
Follow these rules above, then collect the sub graph OutputGradients/InputGradients as the NetOp's and return it.