3.3 KiB
Distributed training overview doc
Currently Paddle Fluid use parameter server architecture to support distributed training.
For synchronous and asynchronous training, the differences are mostly in the logic of parameter server. Now we have already support synchronous training.
Synchronous training
The training process of synchronous training is:
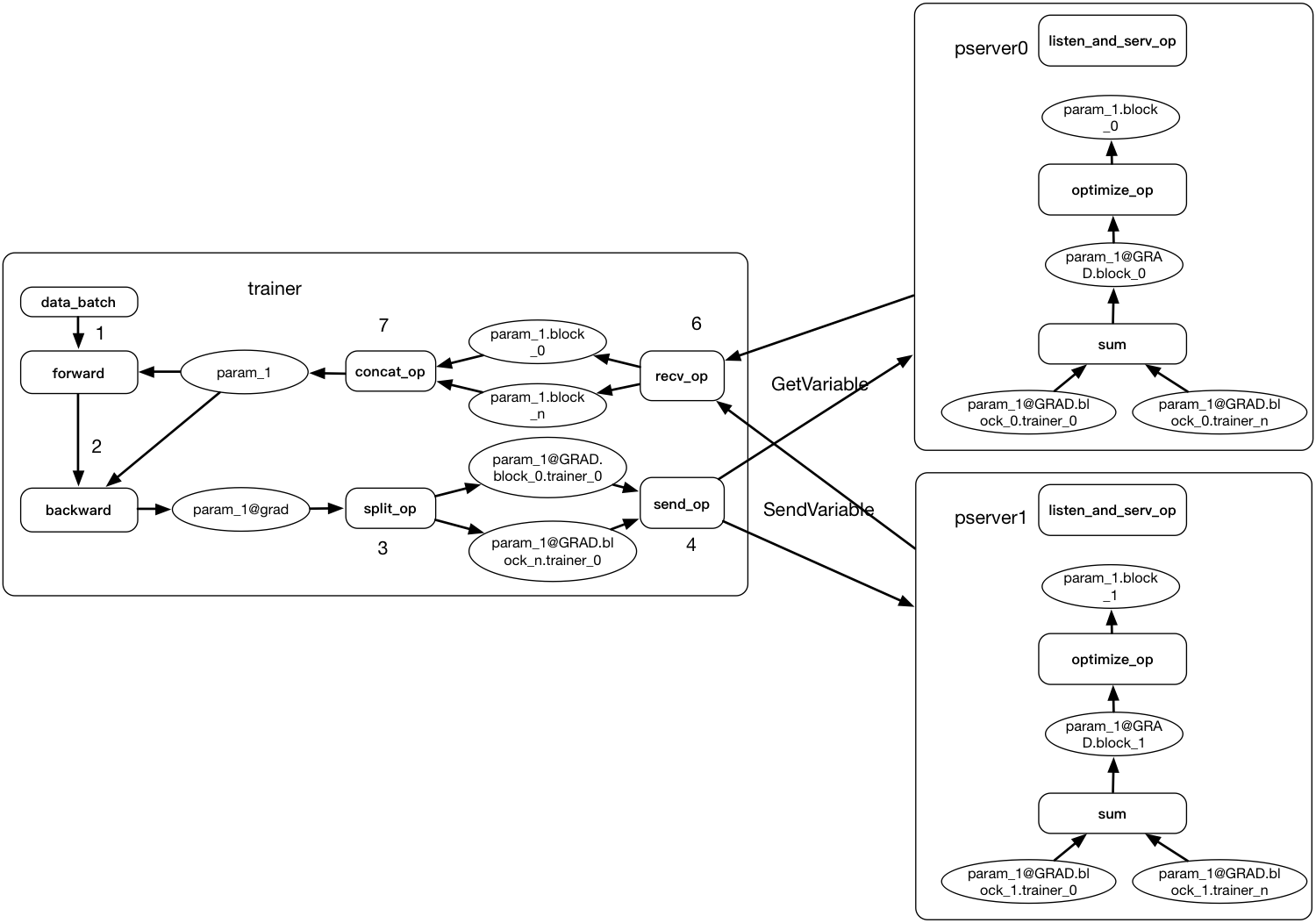
- Pserver
- set
barrier_condition_to 0 and waits for trainers to send gradient.
- set
- Trainer
- Trainer read minibatch of data, run forward-backward with local parameter copy and get the gradients for parameters.
- Trainer use split op to split all the gradient into blocks. The split method is determined at compile time.
- Trainer use send_op to send all the split gradients to corresponding parameter server.
- After trainer send all the gradients, it will send a
BATCH_BARRIER_MESSAGEto all pservers. - Trainer call GetVariable to pserver and wait for
barrier_condition_on pserver to be 1.
- Pserver
- Pserver will count the number of
BATCH_BARRIER_MESSAGE. - When the count of
BATCH_BARRIER_MESSAGEis equal to the number of Trainer. Pserver thinks it received all gradient from all trainers. - Pserver will run the optimization block to optimize the parameters.
- After optimization, pserver set
barrier_condition_to 1. - Pserver wait for
FETCH_BARRIER_MESSAGE.
- Pserver will count the number of
- Trainer.
- The trainer uses GetVariable to get all the parameters from pserver.
- Trainer sends a
FETCH_BARRIER_MESSAGEto each pserver.
- Pserver.
- when the number of
FETCH_BARRIER_MESSAGEreach the number of all trainers. Pserver think all the parameters have been got. it will go back to 1. to setbarrier_condition_to 0.
- when the number of
Asynchronous training
In the above process. There are two barriers for all trainers to synchronize with each other. In asynchronous training, these two barriers are not needed. The trainer can just send gradients to pserver and then get parameters back.
The training process of asynchronous training can be:

-
Pserver:
- Each parameter has a queue to receive its gradient from trainers.
- Each parameter has a thread to read data from the queue and run optimize block, using the gradient to optimize the parameter.
- Using an independent thread to handle RPC call
GetVariablefor trainers to get parameters back.(Maybe here we should use a thread pool to speed up fetching the parameters.)
-
Trainer:
- Trainer read a batch of data. Run forward and backward with local parameter copy and get the gradients for parameters.
- Trainer split all gradients to blocks and then send these gradient blocks to pservers(pserver will put them into the queue).
- Trainer gets all parameters back from pserver.
Note:
There are also some conditions that need to consider. For exmaple:
- If trainer needs to wait for the pserver to apply it's gradient and then get back the parameters back.
- If we need a lock between parameter update and parameter fetch.
- If one parameter must be on one server, or it can also be split and send to multiple parameter servers.
The above architecture of asynchronous training can support different mode, we can have a detailed test in the future for these problems.