6.9 KiB
Batch Normalization
What is batch normalization
Batch normalization is a frequently-used method in deep network training. It adjusts the mean and variance of a layer's output, and make the data distribution easier for next layer's training.
The principle of batch normalization can be summarized into a simple function:
y = (x - E[x]) / STD[x]) * scale + bias
x is a batch of output data of a certain layer. E[x] and STD[x] is the mean and standard deviation of x, respectively。 scale and bias are two trainable parameters. The training of batch normalization layer equals to the learning of best values of scale and bias.
In our design, we use a single operator(batch_norm_op) to implement the whole batch normalization in C++, and wrap it as a layer in Python.
Differences with normal operators
batch_norm_op is a single operator. However, there are a few differences between BatchNormOp and normal operators, which we shall take into consideration in our design.
-
batch_norm_opshall behave differently in training and inferencing. For example, during inferencing, there is no batch data and it's impossible to computeE[x]andSTD[x], so we have to use anestimated_meanand anestimated_varianceinstead of them. These require our framework to be able to inform operators current running type (training/inferencing), then operators can switch their behaviors. -
batch_norm_opshall have the ability to maintainestimated_meanandestimated_varianceacross mini-batch. In each mini-batch,estimated_meanis iterated by the following equations:
if batch_id == 0
estimated_mean = E[x]
else
estimated_mean = estimated_mean * momentum + (1.0 - momentum_) * E[x]
The iterating of estimated_variance is similar. momentum is an attribute, which controls estimated_mean updating speed.
Implementation
Batch normalization is designed as a single operator is C++, and then wrapped as a layer in Python.
C++
As most C++ operators do, batch_norm_op is defined by inputs, outputs, attributes and compute kernels.
Inputs
x: The inputs data, which is generated by the previous layer.estimated_mean: The estimated mean of all previous data batches. It is updated in each forward propagation and will be used in inferencing to take the role ofE[x].estimated_var: The estimated standard deviation of all previous data batches. It is updated in each forward propagation and will be used in inferencing to take the role ofSTD[x].scale: trainable parameter 'scale'bias: trainable parameter 'bias'
Outputs
y: The output data.batch_mean: The mean value of batch data.batch_var: The standard deviation value of batch data.saved_mean: Updatedestimated_meanwith current batch data. It's supposed to share the memory with inputestimated_mean.saved_var: Updatedestimated_varwith current batch data. It's supposed to share the memory with inputestimated_var.
Attributes
is_infer: bool. If true, runbatch_norm_opin inferencing mode.use_global_est: bool. If true, usesaved_meanandsaved_varinstead ofE[x]andSTD[x]in trainning.epsilon: float. The epsilon value to avoid division by zero.momentum: float. Factor used inestimated_meanandestimated_varupdating. The usage is shown above.
Kernels
The following graph showes the training computational process of batch_norm_op:
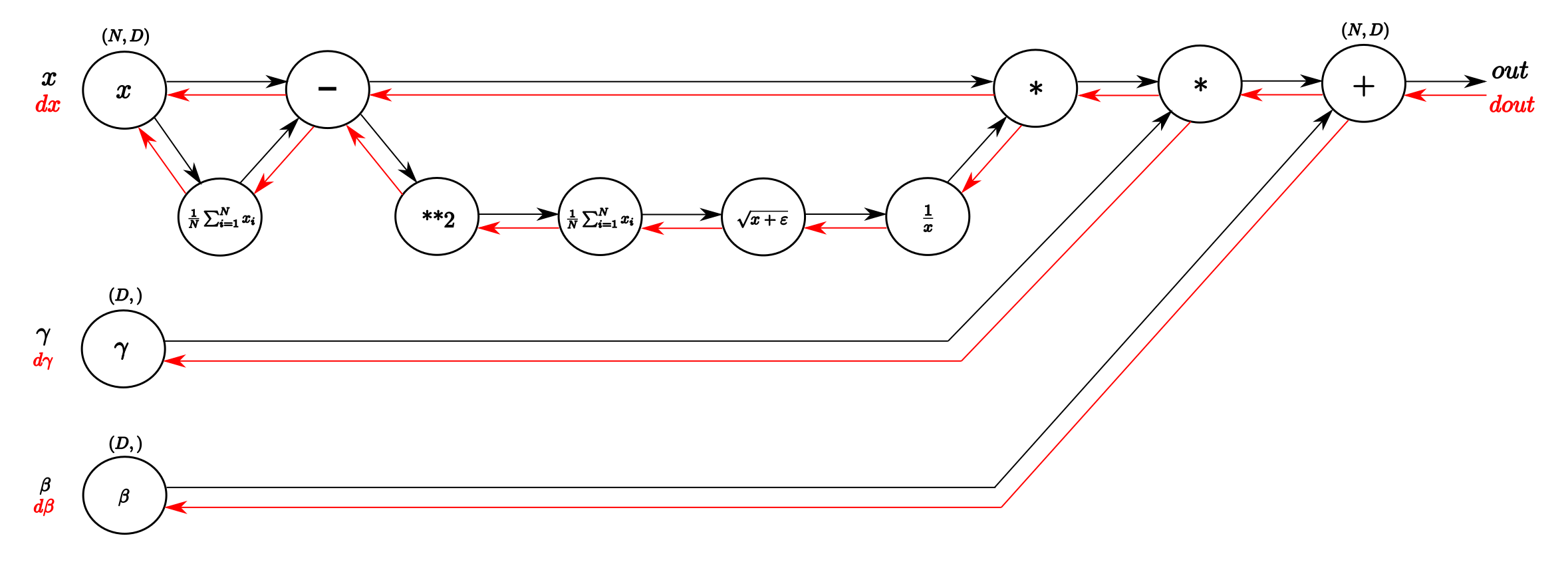
cudnn provides APIs to finish the whole series of computation, we can use them in our GPU kernel.
Python
batch_norm_op is warpped as a layer in Python:
def batch_norm_layer(net,
input,
output,
scale,
bias,
use_global_est = False,
epsilon = 1e-6,
momentum = 0.99):
mean_cache = scope.new_var(name = 'estimated_mean', trainable = False)
var_cache = scop.new_var(name = 'estimated_var', trainable = False)
batch_mean = scope.new_var(name = 'batch_mean')
batch_var = scope.new_var(name = 'batch_var')
batch_norm_op = Operator('batch_norm_op',
x = input,
estimated_mean = mean_cache,
estimated_mean = var_cache,
scale = scale,
bias = bias,
y = output,
batch_mean = batch_mean,
batch_var = batch_var,
saved_mean = mean_cache,
saved_var = var_cache,
is_infer = False,
use_global_est = use_global_est,
epsilon = epsilon,
momentum = momentum)
net.append_op(batch_norm_op)
return output
Because Python API has not been finally decided, the code above can be regarded as pseudo code. There are a few key points we shall note:
-
estimated_meanandestimated_varare assigned the same variables withsaved_meanandsaved_varrespectively. So they share same the memories. The output mean and variance values(saved_meanandsaved_var) of a certain batch will be the inputs(estimated_meanandestimated_var) of the next batch. -
is_inferdecided whetherbatch_norm_opwill run in training mode or inferencing mode. However, a network may contains both training and inferencing parts. And user may switchbatch_norm_op's running mode in Pythonforloop like this:
for pass_id in range(PASS_NUM):
# ...
net.train() # run training model
if pass_id % 100 == 0:
net.infer(test_image) # run inferencing model
# ...
is_infer is an attribute. Once an operator is created, its attributes can not be changed. It suggests us that we shall maintain two batch_norm_op in the model, one's is_infer is True(we call it infer_batch_norm_op) and the other one's is False(we call it train_batch_norm_op). They share all parameters and variables, but be placed in two different branches. That is to say, if a network contains a batch_norm_op, it will fork into two branches, one go through train_batch_norm_op and the other one go through infer_batch_norm_op:

Just like what is shown in the above graph, the net forks before batch_norm_op and will never merge again. All the operators after batch_norm_op will duplicate.
When the net runs in training mode, the end of the left branch will be set as the running target, so the dependency tracking process will ignore right branch automatically. When the net runs in inferencing mode, the process is reversed.
How to set a target is related to Python API design, so I will leave it here waiting for more discussions.